I love the use of semantic versioning. It provides clear guidelines when an API version number should be bumped. In particular, if a change to an API breaks backward compatibility, the major version identifier must be updated. Thus, when as a client of such an API I see a minor or patch update, I can safely upgrade, since these will never break my build.
But to what extent are people actually using the guidelines of semantic versioning? Has the adoption of semantic versioning increased over time? Does the use of semantic versioning speedup library upgrades? And if there are breaking changes, are these properly announced by means of deprecation tags?
To better understand semantic versioning, we studied seven years of versioning history in the Maven Central Repository. Here is what we found.
Versioning Policies
Semantic Versioning is a systematic approach to give version numbers to API releases. The approach has been developed by Tom Preston-Werner, and is advocated by GitHub. It is “based on but not necessarily limited to pre-existing widespread common practices in use in both closed and open-source software.”
In a nutshell, semantic versioning is based on MAJOR.MINOR.PATCH identifiers with the following meaning:
- MAJOR: increment when you make incompatible API changes
-
MINOR: increment when you add functionality in backward compatible manner
-
PATCH: incremented when you make backward-compatible bug fixes
Versioning in Maven Central
To understand how developers actually use versioning policies, we studied 7 years of history of maven. Our study comprises around 130,000 released jar files, of which 100,000 come with source code. On average, we found around 7 versions per library in our data set.
The data set runs from 2006 to 2011, so predates the semantic versioning manifesto. Since the manifesto claims to be based on existing practices, it is interesting to investigate to what extent API developers releasing via maven have adhered to these practices.
As shown below, in Maven Central, the major.minor.patch scheme is adopted by the majority of projects.

Breaking Changes
To understand to what extent version increments correspond to breaking changes, we identified all “update-pairs”: A version as well as its immediate successor of a given maven package.
To be able to assess semantic versioning compliance, we need to determine backward compatibility for such update pairs. Since in general this is undecidable, we use binary compatibility as a proxy. Two libraries are binary compatible, if interchanging them does not force one to recompile. Examples of incompatible changes are removing a public method or class, or adding parameters to a public method.
We used the Clirr tool to detect such binary incompatibilities automatically for Java. For those interested, there is also a SonarQube Clirr plugin for compatibliity checking in a continuous integration setting; An alternative tool is japi.
Major versus Minor/Patch Releases
For major releases, breaking changes are permitted in semantic versioning. This is also what we see in our dataset: A little over 1/3d of the major releases introduces binary incompatibilities:

Interestingly, we see a very similar figure for minor releases: A little over 1/3d of the minor releases introduces binary incompatibilities too. This, however, is in violation with the semantic versioning guidelines.

The situation is somewhat better for patch releases, which introduce breaking changes in around 1/4th of the cases. This nevertheless is in conflict with semantic versioning, which insists that patches are compatible.

Overall, we see that minor and major releases are equally likely to introduce breaking changes.
The graph below shows that these trends are fairly stable over time. Minor (~40%) and patch releases (~45%) are most common, and major releases (~15%) are least common.
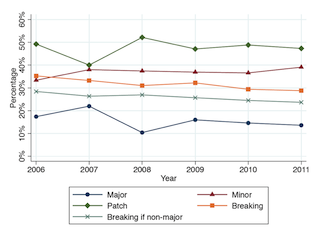
The orange line indicates releases with breaking changes: Around 30% of the releases introduce breaking changes — a number that is slightly decreasing over time, but still at 29%.
Of these releases with breaking changes, the vast majority is non-major (the crossed green line at ~25%). Thus, 1/4th of the releases does not comply with semantic versioning.
Deprecation to the Rescue?
The above analysis demonstrates a deep need to introduce breaking changes: appearantly, developers wish to introduce breaking changes in 30% of their API releases.
Apart from requiring that such changes take place in major releases,
semantic versioning insists on using deprecation to announce such changes. In particular:
Before you completely remove the functionality in a new major release there should be at least one minor release that contains the deprecation so that users can smoothly transition to the new API.
Given the many breaking changes we saw, how many deprecation tags would there be?
At the library level, 1000 out of 20,000 libraries (5%) we studied include at least one depracation tag.
When we look at the individual method level, we find the following:
- Over 86,000 public methods are removed in a minor release, without any deprecation tag.
- Almost 800 public methods receive a deprecation tag in their life span: These methods, however, are never removed.
- 16 public methods receive a deprecation tag that is subsequently undone in a later release (the method is “undeprecated”)
That is all we found. In other words, we did not find a single method that was deprecated according to the guidelines of semantic versioning (deprecate in minor, then delete in major).
Furthermore, the worst behavior (deletion in minor without deprecation, over 86,000 methods) occurs hundred times more often than the best behavior witnessed (deprecation without deletion, almost 800 methods)
Discussion
Our findings are based on a somewhat older dataset obtained from maven. It might therefore be that adherence to semantic versioning at the moment is higher than what we report.
Our findings also take breaking changes to any public method or class into account. In practice, certain packages will be considered as API only, whereas others are internal only — yet declared public due to the limitations of the Java modularization system. We are working on a further analysis in which we explicitly measure to what extent the changed public methods are used. Initial findings within the maven data set suggest that there are hundreds of thousands of compilation problems in clients caused by these breaking changes — suggesting that it is not just internal modules containing these changes.
Some non-Java package managers explicitly have adopted semantic versioning. A notable example is npm, and also nuget has initiated a discussion. While npm has a dedicated library to determine version orderings according to the Semantic Versioning standard, I am not aware of Javascript compatibility tools that are used to check for breaking changes. For .NET (nuget) tools like Clirr exists, such as LibCheck, ApiChange, and the NDepend build comparison tools. I do not know, however, how widespread their use is.
Last but not least, binary incompatibility, as measured by Clirr, is just one form of backward incompatibility. An API may change the behavior of methods as well, in breaking ways. A way to detect those might be by applying old test suites to new code — which we have not done yet.
Conclusion
Breaking API changes are a fact of life. Therefore, meaningful version identifiers are a cause worth fighting for. Thus:
- If you adopt semantic versioning for your API, double check that your minor and patch releases are indeed backward compatible. Consider using tools such as clirr, or a dedicated test suite.
-
If you rely on an API that claims to be following semantic versioning, don’t put too much faith in backward compatibility promises.
-
If you want to follow semantic versioning, be prepared to bump the major version identifier often.
-
Should you need to introduce breaking changes, do not forget to announce these with deprecation tags in minor releases first.
-
If you are in research, note that the problems involved in preventing, encapsulating, detecting, and handling breaking changes are tough and real. Backward compatiblity deserves your research attention.
The full details of our study are published in our paper presented (slides) at the IEEE International Conference on Source Analysis and Manipulation (SCAM), held in Victoria, BC, September 2014.
This post is based on joint work by Steven Raemaekers and Joost Visser, both from the Software Improvement Group.
© Copyright Arie van Deursen, October 2014.
EDIT, November 2014
If you are a Java developer and serious about semantic versioning, then checkout this open source semantic versioning checking tool. It is available on Maven Central and on GitHub, and it can check differences, validate version numbers, and suggest proper version numbers for your new jar release.