A year ago, more than a dozen influential research funders in Europe launched Plan S. This plan poses, from 2021 onwards, strict requirements on open access publishing of any research funded through the Plan S coalition. To understand what this means for my field of research, software engineering, I did some data collection. My data suggests that 14% (one out of seven) of the published papers are affected, meaning that conferences may lose 14% of their papers, unless publishers take action.
Plan S in a Nutshell
Plan S is an initiative launched by:
- The European Union, which runs the Horizon Europe program of €100 billion (over 113 billion US dollars). It is the successor to H2020, and includes funding for the prestigious personal grants of the European Research Council (ERC).
- Twelve national research funding organizations, from various European countries, such as The Netherlands (where I live), the United Kingdom, and Austria.
The aim of these Plan S “funders” (collectively called “Coalition S”), is that
With effect from 2021, all scholarly publications on the results from research funded by public or private grants provided by national, regional and international research councils and funding bodies, must be published in Open Access Journals, on Open Access Platforms, or made immediately available through Open Access Repositories without embargo.
The coalition has taken an axiomatic approach to expressing its plans, starting with 10 principles, followed by a Guidance to the Implementation. The results is a somewhat hard to understand document, in which there are multiple ways to become Plan S compliant.
In all forms of Plan S compliance the Creative Commons license plays a key role. As Plan S (under the header Rights and Licensing) puts it:
The public must be granted a worldwide, royalty-free, non-exclusive, irrevocable license to share (i.e., copy and redistribute the material in any medium or format) and adapt (i.e., remix, transform, and build upon the material) the article for any purpose, including commercial, provided proper attribution is given to the author.
This, thus, corresponds to the Creative Commons Attribution license, also known as CC BY. Note that this is a very generous license, essentially allowing anyone to do anything with the paper. Traditionally, publishers do not like this, as they wish to keep exclusive control over who distributes the paper.
Strictly speaking, Plan S does not require CC BY per se, but authors need to ask permission for any other license. For the CC BY-SA “Share-Alike” variant of the license permission will be granted automatically, but for CC BY-ND “No Derivatives” permission needs to be asked. Coalition S explicitly indicates that CC BY-NC “Non-Commercial” is not allowed:
We will not accept a Non-Commercial restriction on the re-use of research results.
Given this CC BY starting point, Plan S distinguishes three routes to compliance:
- Open access venues: The conference or journal is gold open access, meaning all papers in it are freely available. This is “the ideal” case, from Plan S perspective, and compliant. Open access fees (“Article Processing Charges”) are common in this route, and will be refunded by Coalition S.
- Subscription-based venues: These by themselves are non-compliant, but can be made compliant if the author immediately (no embargo) deposits the Author’s Accepted Manuscript (AAM) in a compliant repository with a CC BY license. This license is a complicating factor, since many publishers pose restrictions on redistribution of self-archived papers (they are self-archived, and no one else can do this — which is at odds with the sharing principle of CC BY). If such restrictions exist, a way out can exist if the venue permits hybrid open access, in which authors can pay an extra fee to make their own article open access available with a CC BY license. This model is offered by many publishers, but not by all. Note, however, that in Plan S, while this route is “compliant”, Plan S does not refund the APC fees.
- Subscrition venues in transition: If the conference or journal is not open access yet, but in transition towards a full open access model by 2024, the publisher and Plan S can agree on “transformative arrangements”. In this case the paper will be compliant, and if there are fees involved they will (likely) be covered.
The 10 principles also address other issues relevant to open access: it requires that “the structure of fees must be transparent” (principle 05, suggesting that some of the current article processing charges are unexplainably high), and warns that the funders will monitor compliance and sanction non-compliant beneficiaries/grantees (principle 09, a direct threat to me).
Plan S should start in 2021, although publishers can earn some extra time by participating in the above-mentioned “transformative arrangements”.
Plan S Compliance in Software Engineering Research
To understand whether Plan S compliant publishing in my area of research, software engineering, is possible at the moment, I looked at the top 20 venues in the area of Software Systems, according to Google Metrics.
In these top 20 venues, just three are gold open access: POPL and OOPSLA, both published by ACM SIGPLAN, and ETAPS TACAS, published by Springer. It is in these venues that authors funded through Coalition S, can safely publish, following the gold open access route to compliance. Their open access fees will be covered by the Coalition S funders.
The remaining 17 are closed access subscription venues, published by ACM, IEEE, Elsevier and Springer. Authors who wish to publish there, and who need to be compliant with Plan S, would then have to resort to the self-archiving route.
Since the self-archiving constraints of these four publishers do not permit the use of CC BY without a fee, the hybrid route applies, in which (1) authors pay a fee; (2) the publisher distributes with CC BY; and (3) the author shares on a Plan S compliant repository. Note that this route is compliant, but that the fee is not refunded by Coalition S.
This self-archiving route works for IEEE journals, but not for IEEE conferences. This is because for IEEE conferences presently authors do not have the option to pay a fee to publish just their own paper open access (unlike ACM). As stated by IEEE in their FAQ on the “IEEE Policy Regarding Authors Rights to Post Accepted Versions of Their Articles”:
Currently IEEE does not have an Open Access program for conference articles.
In other words: Conferences published by IEEE are not Plan S compliant, not even with the green open access route (as IEEE does not permit CC BY).
Of the 20 venues, IEEE is the sole publisher of two conferences (ICSME and SANER), one magazine (IEEE Software), and the co-publisher of another three (ICSE, SANER, MSR) which are published alternatingly by IEEE or ACM.
In summary, of the 20 top venues:
- Three are compliant through gold open access.
- Eleven are compliant through a fee-based hybrid model with CC BY.
- Three are half of the time compliant through a fee-based hybrid model with CC BY, the other half non-compliant.
- Three can presently not be made compliant.
Note that other fields may fare better: top conferences in security (Usenix), AI (AAAI, NIPS), or OOPSLA/POPL/ICFP sponsored by SIGPLAN are all full gold open access. This, however, seems the exception rather than the rule.
Plan S Rationale
With Plan S requiring many publishers to change their policies, one may wonder what the rationale behind this plan is. The way I see it, the key reason for the European funders to propose this plan is leverage, in the following ways:
- The European Union as a whole will benefit more from their €100 billion investment, if any (European) citizen can freely access the resulting knowledge;
- Research is never conducted in isolation. Progress in research is not just visible in papers directly funded through a project, but also in subsequent papers building on top of those results (refuting, strengthening, criticizing, or expanding them). The more venues are open access, the higher the chance that these follow up results are also published as open access.
- The universities in the European Union together will benefit financially if the publishing market shifts towards open access: The current profit margins of up to 40% of publishing giants like Elsevier are a waste of tax payer money that instead should be directly invested in research and education, the exact same causes that the EU and its Horizon Europe program seeks to advance as well. Pumping €100 billion into a system that wastes money at scale is ineffective.
Furthermore, note that this coalition works in all areas of research, including climate change, health care, and artificial intelligence. From the European perspective, the world needs informed societal debate about these topics. To that end, the EU is committed to maximizing the free availability of any research it is funding.
Last but not least, Coalition S is working hard to expand the list of funders, talking to both China and India, for example. Also, Jordania and Zambia have already joined, as well as the Bill and Melinda Gates Foundation (though their presence in computer science research is limited, compared to, e.g., China).
Impact on Software Engineering Conferences
With software engineering venues so clearly affected by Plan S, the next question is how many papers will be affected. Thus, I decided to collect some data, to measure the impact of Plan S in my field.
Since conferences (with full length rigorously reviewed papers) are dominant in software engineering, I focused on these. I picked two editions of ICSE and ESEC/FSE (for which I am a member of the steering committee) and for the smaller and more specialized ISSTA conference (which I happened to attend this summer).
For each published paper, I manually checked the acknowledgments to see whether the authors were beneficiaries from any of the Plan S funders. I did this for the main (technical research) track papers only, and not for, e.g., demonstration sub-tracks.
The results (also available as spreadsheet) are as follows:
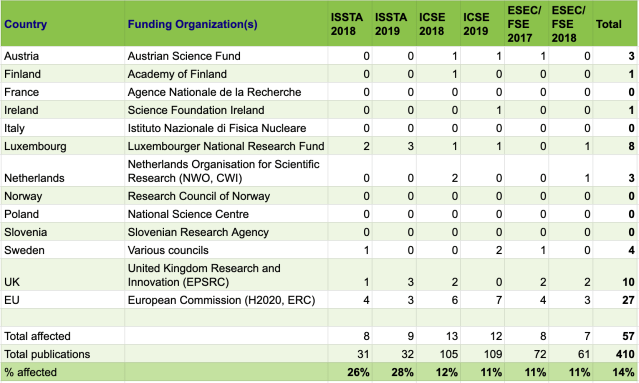
A few results stand out:
- Overall, 14% (1 in 7) of the papers currently receive grants from Coalition S.
- The two big conferences, ICSE (over 1000 participants) and ESEC/FSE (over 300 participants), exhibit an impact on around 11-12% of the papers.
- For the smaller ISSTA conference, more than 25% of the papers are (co-)funded through Coalition S. This number reflects the composition of the community, and the impact is enlarged by the small total number of papers. Should the affected researchers decide not to submit to ISSTA anymore, this may constitute an existential threat to the conference.
- The EU is by far the biggest funder, with researchers and industry from many countries benefiting from participation in large EU projects. Furthermore, the EU ERC (Advanced) Grants are extremely prestigious (€2.5 million) and have been won by leaders in the software engineering field such as (in the collected data) Carlo Ghezzi, Mark Harman, Bashar Nuseibeh, and Andreas Zeller.
- The UK is the second biggest funder, mostly through its EPSRC program. This is the UK’s national program, unrelated to the European Union. Thus, EPSRC’s participation in Coalition S will not be affected by Brexit (apart from increased financial pressure on ESPRC’s overall budget as the UK’s economy is shrinking).
- While a small country with limited funds, Luxembourg is very active in the area of software engineering, causing high impact for, e.g., the ISSTA conference.
The 14% I found is substantially higher than the estimate of 6% impact found by Clarivate Analytics (cited by the ACM), and the 5% found by the ACM itself. If anything, this factor 3 or even factor 5 with ISSTA difference calls for a detailed assessment for each venue affected.
My data is based on what I saw in the acknowledgments: In reality it is likely that more papers are affected. You can check your own papers in my on line spreadsheet — corrections are welcome.
Collecting the data takes took me around a minute per paper. You are cordially invited to repeat this exercise for your own favorite conference or journal (TSE, EMSE, JSS, MSR, ICSME, RE, MODELS, …), and I will do my best to reflect your data in this post. If you’re a conference organizer, the safest thing to do is survey authors about their funding, enquiring about Coalition S based funding explicitly.
There is a another point to be made that required little data gathering.
The 14% figure relates to impact on the conference. Individual researchers can be affected much more. Our group at TU Delft, for example, has been very successful in attracting substantial funding both from the EU and from the Dutch NWO. As a consequence, for me personally, half of my publications will be affected. For some new PhD students starting in my group funded on such projects all publications will be affected.
A Call for Action
Clearly, the impact of Plan S can be substantial, on individual researchers as well as on conferences and journals.
This calls for action.
ACM, as one of the leading publishers in computer science, shared an update on their Plan S progress in their July 2019 news letter. It states:
It is worth noting that ACM has been working with various consortia in the US, Europe, and elsewhere on a framework for transitioning the traditional ACM Digital Library licensing (subscription) model to a Gold Open Access model utilizing an innovative “transformative agreement” model. More details will be announced later in 2019 as the first of these Agreements are executed; once these are in place, all ACM Publications will comply with the majority of Plan S requirements.
This is good news, and certainly not a simple undertaking. I sincerely hope that ACM will be able to meet not just the majority, but all requirements, and for all conferences and journals. This essentially implies a change of business model for the ACM Digital Library, from a subscription based to an author-(institution)-pays model. This in itself will not be easy, and is further complicated by several constraints and strong criteria imposed by Plan S, for example concerning cost transparency. The key challenge will be to convince Coalition S that these criteria are indeed met.
The ACM Special Interest Group on Programming Languages, SIGPLAN, meanwhile, sets an example on how to progress within the current setting. The research papers of three of its key conferences are published as part of the Proceedings of the ACM in Programming Languages. This is a Gold Open Access journal in which different volumes are devoted to different conferences. The POPL, OOPSLA, and ICFP conferences have adopted this model, and hence are fully open access. To quote the Inaugural Editorial Message by Philip Wadler:
PACMPL is a Gold Open Access journal. It will be archived in ACM’s Digital Library, but no membership or fee is required for access. Gold Open Access has been made possible by generous funding through ACM SIGPLAN, which will cover all open access costs in the event authors cannot. Authors who can cover the costs may do so by paying an Article Processing Charge (APC). PACMPL, SIGPLAN, and ACM Headquarters are committed to exploring routes to making Gold Open Access publication both affordable and sustainable.
The ACM SIG for Software Engineering, SIGSOFT, so far has not taken action along these lines. Nevertheless, this is simple to do, especially since SIGPLAN has laid out all the ground work.
Furthermore, last year, we as ACM SIGSOFT members elected Tom Zimmermann as our chair. In his statement for the elections he wrote:
We should make gold open access a priority for SIGSOFT
He also provided details on how to achieve this, mostly along the lines of SIGPLAN. By electing him, we as ACM SIGSOFT members gave him the mandate to carry this out. This will not be easy to do, but calls for all support from the full software engineering research community to help the ACM SIGSOFT leadership with this important mission.
The other main non-profit society publisher in software engineering is the IEEE. IEEE publishes various conferences and journals in software engineering on its own, such as ICSME, MODELS, RE and ICST. Furthermore, several major conferences are co-sponsored by IEEE and ACM together, such as ICSE and ASE.
Unfortunately, I have not been able to find on line information about IEEE’s vision on Plan S, and its impact on the conference proceedings published by the IEEE. This makes it very unclear what, from 2021 onwards, the publication options are for many software engineering conferences.
Nevertheless, it is my hope that IEEE will embrace Plan S, and move to open access conference proceedings, as many other society publishers have done.
This, then, will open the floor to joint open access publications, for example through the new fully open access “Proceedings of the ACM in Software Engineering”.
Version History
- Version 0.4, 20-08-2019. First public version.
- Version 0.5, 25-08-2019. Major update to reflect that self-archiving route can aslo be used to meet Plan S requirements.
- Version 0.6, 26-08-2019. Small updates about CC BY options.
- Version 0.7, 28-08-2019. Major update about repository route in combination with CC BY and hybrid open access, and transformative arrangements.
- Version 0.8, 30-08-2019. Add links to IEEE open access faq/
- Version 0.9, 04-09-2019. Small typos fixed
Note: IANAL — use this information at your own risk.
Acknowledgements: Thanks to Diomidis Spinellis, Simon Bains, Jeroen Bosman, Bianca Kramer, and Jeroen Sondervan for feedback on an earlier drafts on this post.
License: Copyright (c) Arie van Deursen, 2019. Licensed under CC BY.
Slide Deck