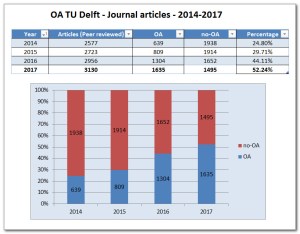
In 2016, TU Delft adopted Elsevier Pure as its database to keep track of all publications from its employees.
At the same time, TU Delft has adopted a mandated green open access policy. This means that for papers published after May 2016, an author-prepared version (pdf) must be uploaded into Pure.
I am very happy with this commitment to green open access (and TU Delft is not alone). This decision also means, however, that we as researchers need to do some extra work, to make our author-prepared versions available.
To make it easier for you to upload your papers and comply with the green open access policy, here are some suggestions based on my experience so far working with Pure.
I can’t say I’m a big fan of Elsevier Pure. In the interest of open access, however, I’m doing my best to tolerate the quirks of Pure, in order to help the TU Delft to share all its research papers freely and persistently with everyone in the world.
Elsevier Pure is used at hundreds of different universities. If you work at one of them, this post may help you in using Pure to make your research available as open access.

Anyone can browse publications in Pure, available at https://pure.tudelft.nl.
All pages have persistent URL’s, making it easy to refer to a list of all your publications (such as my list), or individual papers (such as my recent one on crash reproduction). For all recent papers I have added a pdf of the version that we as authors prepared ourselves (aka the postprint), as well as a DOI link to the publisher version (often behind a paywall).
Thus, you can use Pure to offer, for each publication, your self-archived (green open access) version as well as the final publisher version.
Moreover, these publications can be aggregated to the section, department, and faculty level, for management reporting purposes.
In this way, Pure data shows the tax payers how their money is spent on academic research, and gives the tax payer free access to the outcomes. The tax payer deserves it that we invest some time in populating Pure with accurate data.
To enter publications into pure, you’ll need to login. On https://pure.tudelft.nl, in the footer at the right, you’ll find “Log into Pure”. Use your TU Delft netid.
If you’re interested in web applications, you will quickly recognize that Pure is a fairly old system, with user interface choices that would not be made these days.
You can start entering a publication by hitting the big green button “Add new” at the top right of the page. It will open a brand new browser window for you.
In the new window, click “Research Output”, which will turn blue and expand into three items.
Then there are several ways to enter a publication, including:
- Import via Elsevier Scopus, found via “Import from Online Source”. This is by far the easiest, if (1) your publication venue is indexed by Scopus, (2) it is already visible at Scopus (which typically takes a few months), and if (3) you can find it on Scopus. To help Scopus, I have set up an ORCID author identifier and connected it to my Scopus author profile.
-
Import via Bibtex, found via “Import from file”. If you click it, importing from bibtex is one of the options. You can obtain bibtex entries from DBLP, Google Scholar, ACM, your departmental publications server, or write them by hand in your favorite editor, and then copy paste them into Pure.
-
Entering details via a series of buttons and forms (“Create from template”). I recommend not to use this option. If you go against this advice, make sure that if you want to enter a conference paper, you do not pick the template “Paper/contribution to conference”, as you should pick “Conference Contribution/Chapter in Conference Proceedings” instead. Don’t ask me why.
In all cases, yet another browser window is opened, in which you can inspect, correct, and save the bibliographic data. After saving, you’ll have a new entry with a unique URL that you can use for sharing your publication. The URL will stay the same after you make additional updates.
With each publication, you can add various “electronic versions”.
Each can be a file (pdf), a link to a version, or a DOI. For pdfs you want to upload, make sure you check it meets the conditions under your publisher allows self-archiving.
Pure distinguishes various version types, which you can enter via the “Document version” pull down menu. Here you need to include at least the following two versions:
- The “accepted author manuscript”. This is also called a postprint, and is the version that (1) is fully prepared by you as authors; and that (2) includes all improvements you made after receiving the reviews. Here you can typically upload the pdf as you prepared it yourself.
-
The “final published version”. This is the Publisher’s version. It is likely that the final version is copyrighted by the publisher. Therefore, you typically include a link (DOI) to the final version, and do not upload a pdf to Pure. If you import from Scopus, this field is automatically set.
Furthermore, Pure permits setting the “access to electronic version”, and defining the “public access”. Relevant items include:
- Open, meaning (green) open access. This is what I typically select for the “accepted author manuscript”.
-
Restricted, meaning behind a paywall. This is what I typically select for the final published version.
-
Embargoed, meaning that the pdf cannot be made public until a set date. Can be used for commercial publishers who insist on restricting access to post-prints from institutional repositories in the first 1-2 years.

The vast majority (80%) of the academic publishers permits authors to archive their accepted manuscripts in institutional repositories such as Pure. However, publishers typically permit this under specific conditions, which may differ per publisher. You can check out my Green Open Access FAQ if you want to learn more about these conditions, and how to find them for your (computer science) publisher.
Once uploaded, your pdf is available for download for everyone. Pure adds a cover page with meta-data such as the citation (how it is published) and the DOI to the final version. This cover page is useful, as it helps to meet the intent of the conditions most publishers require on green open access publishing.
Google Scholar indexes Pure, so after a while your paper should also appear on your Scholar page.
Making papers early available is one of the benefits of self-archiving. This can be done in Pure by setting the paper’s “Publication Status”. This field can have the following values:
- “In preparation”: Literally a pre-print. Your paper can be considered a draft and may still change.
- “Submitted”: You submitted your paper to a journal or conference where it is now under review.
- “Accepted/In press”: Yes, paper accepted! This also means that you as an author can share your “accepted author manuscript”.
- “E-Pub ahead of print”: I don’t see how this differs from the Accepted state.
- “Published”: The paper is final and has been officially published.
In my Green Open Access FAQ I provide an answer to the question Which Version Should I Self-Archive.
I typically enter publications once accepted, and share the Pure link with the accepted author manuscript as pre-print link on Twitter or on conference sites (e.g. ICSE 2018)
In particular, I do the following once my paper is accepted:
- I create a bibtex entry for an
@inproceedings (conference, workshop) or @article (journal) publication.
- I upload the bibtex entry into pure.
- I add my own pdf with the author-prepared version to the resulting pure entry
- I set the Publication Status to “Accepted”.
- I set the Entry Status (bottom of the page) to “in progress”
- I save the entry (bottom of the page)
- I share the resulting Pure link on Twitter with the rest of the world so that they can read my paper.
Once the publisher actually manages to publish this paper as well (this may be several months later!), I update my pure entry:
- I add the DOI link to the final published version.
- I provide the missing bibliographic meta-data (page numbers, volume, number, …).
- I set the Publication Status to “Published”.
- I set the Entry Status to “for approval” (by the library who can then change it into an immutable “approved” if they think this is a valid entry).
My preprint links I shared still contain a pointer to the self-archived pdf, but now also to the official version at the publisher for those who have access through the pay wall.
The Pure page for your paper including all meta-information and all versions of that paper (example) in principle is stable, and its URL provide a permanent link (unless you delete it).
You can also directly link to the individual pdfs you upload (example). However, these are more volatile: If you upload a newer version the old link will be dead. Moreover, in some cases the (TU Delft) library has moved pdfs around thereby destroying old pdf links.
Therefore, I recommend to use links to the full record rather than individual pdfs when sharing pure links.
Elsevier does not like it if you self-archive papers published in Elsevier journals into Elsevier Pure. The official rules are that Elsevier journal papers are subject to an embargo, yet at the same time can be published with a CC-BY-NC-ND license on arxiv.
Combining these two leads to the following steps, assuming you have a pre-print (never reviewed), and a post-print (the author-prepared accepted version after review).
- Upload your pre-print onto Arxiv.
- Add a footnote to your post-print stating: This manuscript version is made available under the CC-BY-NC-ND 4.0 license.
- Update your arxiv pre-print with your CC-BY-NC-ND licensed post-print, and add publication details (journal name, volume, issue) to your arxiv entry.
- Create a Pure entry for your journal paper
- Upload the post-print as author-accepted version to your Pure entry, make it available immediately, and set the license to CC-BY-NC-ND.
Note that the Elsevier rules explicitly allow steps 1-3, and in fact insists on the CC-BY-NC-ND license. Elsevier does not suggest you take step 5, but as a consequence of the CC-BY-NC-ND license you are permitted to do so.
What Elsevier would want you to do instead of step 5 is add the postprint to Pure under a (2 year) embargo, thus delaying (green) open access availability by 2 years. Elsevier Pure even supports this embargo option as one of the “access” options, in which you could enter the end-date of such an embargo.
Note: Yes, these steps are annoying. But: at the time of writing (2019), universities in Germany, Sweden, and California have no access to recent papers published by Elsevier. If you want your paper to be read in any of these countries make sure to upload it into your university repository. If you don’t want to go through these steps and you want your paper to be read, I recommend you pick a different publisher.
See also:
Pure contains official employee names as registered by TU Delft.
Some authors publish under different (variants of their) names. For example, Dutch universities have trouble handling the complex naming habits of Portuguese and Brazilian employees.
If Pure is not able to map an author name to the corresponding employee, find the author name in the publication, click edit, and then click “Replace”. This allows searching the TU Delft employee database for the correct person.
If Pure has found the correct employee, but the name displayed is very differently from what is listed on the publication itself, you can edit the author for that publication, and enter a different first and last name for this publication.
If you’re logged in, you can download your publication list in various formats, including BibTex (you’ll find the button for this at the bottom of the page).
I prefer bibtex entries that have a url back to the place where all info is. Therefore, I wrote a little Python script to scrape a Pure web page (mine, yours, or anyone’s), that adds such information.
I use the bibtex entries produced by this script to populate my Orcid profile as well as our Departmental Publication Server with publications from Pure that link back to their corresponding pure page.
Version history
- 20 November 2016: Version 0.1, for internal purposes.
- 07 December 2016: Version 0.2, first public version.
- 14 December 2016: Version 0.3, minor improvements.
- 13 January 2017: Version 0.4, updated Google Scholar information.
- 16 March 2017: Version 0.5, updated approval states based on correction from Hans Meijerrathken.
- 17 March 2017: Version 0.6, life cycle and exporting added.
- 24 November 2017: Version 0.7, simplified life cycle and approval states.
- 03 March 2018: Version 0.8, added info on populating Orcid from Pure.
- 27 July 2018: Version 0.9, added info on permalinks, licensed as CC BY-SA 4.0
- 08 March 2019: Version 1.0, added info on publishing Elsevier papers.
Acknowledgments: Thanks to Moritz Beller for providing feedback and trying out Pure.
© Arie van Deursen, 2018. Licensed under CC BY-SA 4.0.