Arie van Deursen, Alex Nederlof, and Eric Bouwers.
When teaching software architecture it is hard to strike the right balance between practice (learning how to work with real systems and painful trade offs) and theory (general solutions that any architect needs to thoroughly understand).
To address this, we decided to try something radically different at Delft University of Technology:

- To make the course as realistic as possible, we based the entire course on GitHub. Thus, teams of 3-4 students had to adopt an active open source GitHub project and contribute. And, in the style of “How GitHub uses GitHub to Build GitHub“, all communication within the course, among team members, and with external stakeholders took place through GitHub where possible.

- Furthermore, to ensure that students actually digested architectural theory, we made them apply the theory to the actual project they picked. As sources we used literature available on the web, as well as the software architecture textbook written by Nick Rozanski and Eoin Woods.
To see if this worked out, here’s what we did (the course contents), how we did it (the course structure, including our use of GitHub), and what most of us liked, or did not like so much (our evaluation).
Course Contents
GitHub Project Selection
At the start of the course, we let teams of 3-4 students adopt a project of choice on GitHub. We placed a few constraints, such as that the project should be sufficiently complex, and that it should provide software that is actually used by others — there should be something at stake.
Based on our own analysis of GitHub, we also provided a preselection of around 50 projects, which contained at least 200 pull requests (active involvement from a community) and an automated test suite (state of the art development practices).
The projects selected by the students included Netty, Jenkins, Neo4j, Diaspora, HornetQ, and jQuery Mobile, to name a few.
Making Contributions
To get the students involved in their projects, we encouraged them to make actual contributions. Several teams were successful in this, and offered pull requests that were actually merged. Examples include an improvement of the Aurelius Titan build process, or a fix for an open issue in HornetQ. Other contributions were in the form of documentation, for example one team created a (popular) screencast on how to build a chat client/server system with Netty in under 15 minutes, posted on Youtube.
The open source projects generally welcomed these contributions, as illustrated by the HornetQ reaction:
Thanks for the contribution… I can find you more if you need to.. thanks a lot! :+1:
And concerning the Netty tutorial:
Great screencast, fantastic project.
Students do not usually get this type of feedback, and were proud to have made an impact. Or, as the CakePHP team put it:
All in all we are very happy with the reactions we got, and we really feel our contribution mattered and was appreciated by the CakePHP community.

To make it easier to establish contact with such projects, we setup a decidcated @delftswa Twitter account. Many of the projects our students analyzed have their own Twitter accounts, and just mentioning a handle like @jenkinsci or @cakephp helped receive the project’s attention and establish the first contact.
Identifying Stakeholders
One of the first assignments was to conduct a stakeholder analysis:
understanding who had an interest in the project, what their interest was, and which possibly conflicting needs existed.
To do this, the students followed the approach to identify and engage stakeholders from Rozanski and Woods. They distinguish various stakeholder classes, and recommend looking for stakeholders who are most affected by architectural decisions, such as those who have to use the system, operate or manage it, develop or test it, or pay for it.

Aurelius Stakeholders (click to enlarge)
To find the stakeholders and their architectural concerns, the student teams analyzed any information they could find on the web about their project. Besides documentation and mailing lists, this also included an analysis of recent issues and pull requests as posted on GitHub, in order to see what the most pressing concerns of the project at the moment are and which stakeholders played a role in these discussions.
Architectural Views
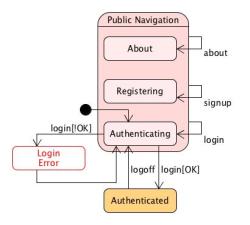
Since Kruchten’s classical “4+1 views” paper, it has been commonly accepted that there is no such thing as the architecture. Instead, a single system will have multiple architectural views.
Following the terminology from Rozanski and Woods, stakeholders have different concerns, and these concerns are addressed through views.
Therefore, with the stakeholder analysis in place, we instructed students to create relevant views, using the viewpoint collection from Rozanski and Woods as starting point.

Rozanski & Woods Viewpoints
Some views the students worked on include:
- A context view, describing the relationships, dependencies, and interactions between the system and its environment. For example, for Diaspora, the students highlighted the relations with users, `podmins’, other social networks, and the user database.
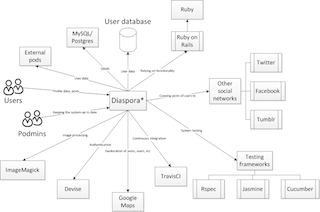
- A development view, describing the system for those involved in building, testing, maintaining, and enhancing the system. For example, for neo4j, students explained the packaging structure, the build process, test suite design, and so on.

- A deployment view, describing the environment into which the system will be deployed, including the dependencies the system has on its runtime environment. For GitLab, for example, the students described the installations on the clients as well as on the server.

Besides these views, students could cover alternative ones taken from other software architecture literature, or they could provide an analysis of the perspectives from Rozanski and Woods, to cover such aspects as security, performance, or maintainability.
Again, students were encouraged not just to produce architectural documentation, but to challenge the usefulness of their ideas by sharing them with the projects they analyzed. This also forced them to focus on what was needed by these projects.
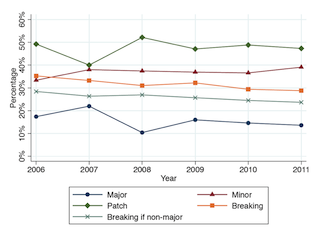
For example, the jQuery Mobile was working on a new version aimed at realizing substantial performance improvements. Therefore, our students conducted a series of performance measurements comparing two versions as part of their assignment. Likewise, for CakePHP, our students found the event system of most interest, and contributed a well-received description of the new CakePHP Events System.
Software Metrics
For an architect, metrics are an important tool to discuss (desired) quality attributes (performance, scaleability, maintainability, …) of a system quantitatevely. To equip students with the necessary skills to use metrics adequately, we included two lectures on software metrics (based on our ICSE 2013 tutorial).
Students were asked to think of what measurements could be relevant for their projects. To that end, they first of all had to think of an architecturally relevant goal, in line with the Goal/Question/Metric paradigm. Goals picked by the students included analyzing maintainability, velocity in responding to bug reports, and improving application responsiveness.
Subsequently, students had to turn their project goal into 3 questions, and identify 2 metrics per question.

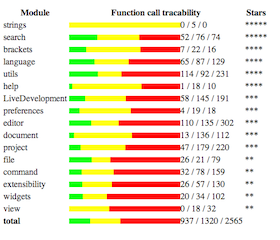
Brackets Analyzability
Many teams not just came up with metrics, but also used some scripting to actually conduct measurements. For example, the Brackets team decided to build RequireJS-Analyzer, a tool that crawls JavasScript code connected using RequireJS and analyzes the code, to report on metrics and quality.
Architectural Sketches
Being an architect is not just about views and metrics — it is also about communication. Through some luck, this year we were able to include an important yet often overlooked take on communication: The use of design sketches in software development teams.
We were able to attract Andre van der Hoek (UC Irvine) as guest speaker. To see his work on design sketches in action, have a look at the Calico tool from his group, in which software engineers can easily share design ideas they write at a sketch board.
In one of the first lectures, Andre presented Calico to the students. One of the early assignments was to draw any free format sketches that helped to understand the system under study.
The results were very creative. The students freed themselves from the obligation to draw UML-like diagrams, and used colored pencils and papers to draw what ever they felt like.

For example, the above picture illustrates the HornetQ API; Below you see the Jenkins work flow, including dollars floating from customers the contributing developers.

Lectures From Industry
Last but not least, we wanted students to meet and learn from real software architects. Thus, we invited presentations from the trenches — architects working in industry, sharing their experience.
For example, in 2013 we had TU Delft alumnus Maikel Lobbezoo, who presented the architectural challenges involved in building the payment platform offered by Adyen. The Adyen platform is used to process gazilions of payments per day, acrross the world. Adyen has been one of the fastest growing tech companies in Europe, and its success can be directly attributed to its software architecture.

Maikel explained the importance of having a stateless architecture, that is linearly scalable, redundant and based on push notifications and idempotency. His key message was that the successful architect possesses a (rare) combination of development skills, communicative skills, and strategical bussiness insight.
Our other guest lecture covered cyber-physical systems: addressing the key role software plays in safety-critical infrastructure systems such as road tunnels — a lecture provided by Eric Burgers from Soltegro. Here the core message revolved around traceability to regulations, the use of model-based techniques such as SysML, and the need to communicate with stakeholders with little software engineering experience.
Course Structure
Constraints
Some practical constraints of the course included:
- The course was worth 5 credit points (ECTS), corresponding to 5 * 27 = 135 hours of work per student.
- The course run for half a semester, which is 10 consecutive weeks
- Each week, there was time for two lectures of 90 minutes each
- We had a total of over 50 students, eventually resulting in 14 groups of 3-4 students.
- The course was intended four 4th year students (median age 22) who were typically following the TU Delft master in Computer Science, Information Architecture, or Embedded Systems.
GitHub-in-the-Course
All communication within the course took place through GitHub, in the spirit of the inspirational video How GitHub uses GitHub to Build GitHub. As a side effect, this eliminated the need to use the (not so popular) Blackboard system for intra-course communication.
From GitHub, we obtained a (free) delftswa organization. We used it to host various repositories, for example for the actual assignments, for the work delivered by each of the teams, as well as for the reading material.
Each student team obtained one repository for themselves, which they could use to collaboratively work on their assignments. Since each group worked on a different system, we decided to make these repositories visible to the full group: In this way, students could see the work of all groups, and learn from their peers how to tackle a stakeholder analysis or how to assess security issues in a concrete system.
Having the assignment itself on a GitHub repository not only helped us to iteratively release and improve the assignment — it also gave students the possibility to propose changes to the assignment, simply by posting a pull request. Students actually did this, for example to fix typos or broken links, to pose questions, to provide answers, or to start a discussion to change the proposed submission date.
We considered whether we could make all student results public. However, we first of all wanted to provide students with a safe environment, in which failure could be part of the learning process. Hence it was up to the students to decide which parts of their work (if any) they wanted to share with the rest of the world (through blogs, tweets, or open GitHub repositories).
Time Keeping
One of our guiding principles in this course was that an architect is always eager to learn more. Thus, we expected all students to spend the full 135 hours that the course was supposed to take, whatever their starting point in terms of knowledge and experience.
This implies that it is not just the end result that primarily counts, but the progress the students have made (although there is of course, a “minimum” result that should be met at least).
To obtain insight in the learning process, we asked students to keep track of the hours they spent, and to maintain a journal of what they did each week.
For reasons of accountability such time keeping is a good habit for an architect to adopt. This time keeping was not popular with students, however.
Student Presentations
We spent only part of the lecturing time doing class room teaching.
Since communication skills are essential for the successful architect,
we explicitly allocated time for presentations by the students:
- Half-way all teams presented a 3-minute pitch about their plans and challenges.
- At the end of the course we organized a series of 15 minute presentations in which students presented their end results.
Each presentation was followed by a Q&A round, with questions coming from the students as well as an expert panel. The feedback concerned the architectural decisions themselves, as well as the presentation style.
Grading
Grading was based per team, and based on the following items:
- Final report: the main deliverable of each team, providing the relevant architectural documentation created by the team.
- Series of intermediate (‘weekly’) reports corresponding to dedicated assignments on, e.g, metrics, particular views, or design sketches. These assignments took place in the first half of the course, and formed input for the final report;
- Team presentations
Furthermore, there was one individual assignment, in which each student had to write a review report for the work of one of the other teams. Students did a remarkably good (being critical as well as constructive) job at this. Besides allowing for individual grading, this also ensured each team received valuable feedback from 3-4 fellow students.
Evaluation
All in all, teaching this course was a wonderful experience. We gave the students considerable freedom, which they used to come up with remarkable results.
A key success factor was peer learning. Groups could learn from each other, and gave feedback to each other. Thus, students not just made an in depth study of the single system they were working on, but also learned about 13 different architectures as presented by the other groups. Likewise, they not just learned about the architectural views and perspectives they needed themselves, but learned from their co-students how they used different views in different ways.
The use of GitHub clearly contributed to this peer learning. Any group could see, study, and learn from the work of any other group. Furthermore, anyone, teachers and students alike, could post issues, give feedback, and propose changes through GitHub’s facilities.
On the negative side, while most students were familiar with git, not all were. The course could be followed using just the bare minimum of git knowledge (add, commit, checkout, push, pull), yet the underlying git magic sometimes resulted in frustration with the students if pull requests could not be merged due to conflicts.
An aspect the students liked least was the time keeping. We are searching for alternative ways of ensuring that time is spent early on in the project, and ways in which we can assess the knowledge gain instead of the mere result.
One of the parameters of a course like this is the actual theory that is discussed. This year, we included views, metrics, sketches, as well as software product lines and service oriented architectures. Topics that were less explicit this year were architectural patterns, or specific perspectives such as security or concurrency. Some of the students indicated that they liked the mix, but that they would have preferred a little more theory.
Conclusion
In this course, we aimed at getting our students ready to take up a leading role in software development projects. To that end, the course put a strong focus on:
- Close involvement with open source projects where something was at stake, i.e., which were actually used and under active development;
- The use of peer learning, leveraging GitHub’s social coding facilities for delivering and discussing results
- A sound theoretical basis, acknowleding that architectural concepts can only be grasped and deeply understood when trying to put them into practice.
Next year, we will certainly follow a similar approach, naturally with some modifications. If you have suggestions for a course like this, or are aware of similar courses, please let us know!
Acknowledgments
A big thank you to all students who participated in IN4315 in 2013,
to jury members Nicolas Dintzner, Felienne Hermans, and Georgios Gousios, and guest lecturers Andre van der Hoek, Eric Burgers, Daniele Romano, and Maikel Lobbezoo for shaping this course!
Further Reading
- Zach Holman. How GitHub uses GitHub to Build GitHub. RubyConf, September 2011.
- Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012, 2nd edition.
- Diomides Spinellis and Georgios Gousios (editors). Beautiful Architecture: Leading Software Engineers Explain How They Think. O’Reilly Media, 2009.
- Amy Brown and Greg Wilson (editors). The Architecture of Open Source Applications. Volumes 1-2, 2012.
- Software Architecture Wikipedia page (thoughtfully and substantially edited by the IFIP Working Group on Software Architecture in 2012)
- Eric Bouwers. Metric-based Evaluation of Implemented Software Architectures. PhD Thesis, Delft University of Technology, 2013.
- Remco de Boer, Rik Farenhorst, Hans van Vliet: A Community of Learners Approach to Software Architecture Education. CSEE&T, 2009.
- Earlier use of GitHub in the class room by Neil Ernst while at UBC: Using GitHub for 3rd Year Software Engineering, and Teaching Advanced Software Engineering.
© Text: Arie van Deursen, Alex Nederlof, and Eric Bouwers, 2013.
© Architectural views: students of the TU Delft IN4315 course, 2013.